The first attempts at machine translation began with using bilingual dictionaries and applying fixed, hand-curated rules for grammar and word reordering. These early attempts did not consistently produce natural sounding translations across an entire language because there were simply too many rules and exceptions to enumerate. Language is incredibly complex and translation even more so. For humans to correctly translate something from one language to another fluently, we need to know the translation of each word in a sentence and in most cases, to understand meaning and context.
There is innate ambiguity in most languages, and it was once believed that only fundamental understanding of words and their meanings could ensure correct translations. To combat the issue of language ambiguity, systems were developed to translate languages into some unambiguous intermediary and then into the target language. While this improved results, there are so many languages and each language is so vast that it is simply not feasible to write rules for disambiguation and translation by hand. This outlook inspired the field of Statistical Machine Translation (SMT). Machines can gather statistics and analyze large parallel corpuses to determine which translations are more likely than others.
While SMT was state of the art until very recently, neural network models for machine translation have been very popular. While statistical phrase-based translation works by translating groups of words in a sentence and then ordering those translated groups properly to form an output, neural networks allow for a single, end-to-end model to process the entire sentence at once. Furthermore, many production translation systems are transitioning to these newer models citing improved translation accuracy and quality.
For an assignment in my Natural Language Processing class as a graduate student at UC Berkeley, I decided to create a recurrent neural network to translate text from English to Portuguese using TensorFlow. To create this model, I adapted a basic sequence-to-sequence recurrent neural network model and incorporated an attention mechanism. The model consists of three recurrent neural networks (RNN): one for encoding the English sentence, one for decoding into Portuguese and an attention mechanism to allow the decoder to selectively use different parts of the encoder’s output. The encoder and decoder are both composed of three stacked Gated Recurrent Unit (GRU) cells. To train my model, I used the English-Portuguese dataset from “Europarl: A Parallel Corpus for Statistical Machine Translation.”
Related: How Google Translate uses machine learning algorithms
Data and Vocabulary
As mentioned before, the dataset used to train the model was the English-Portuguese parallel corpus from Europarl. This dataset consists of 2M parallel sentences, 50M English words and 50M Portuguese words. An exploratory analysis of the data determined the optimal method of tokenization and vocabulary size. For a strict tokenizer, we split words using the Natural Language ToolKit’s (NLTK) word_tokenizer and used this output directly. For a more flexible tokenizer, we lower-cased our inputs and ignored numbers and punctuation. For either tokenizer, the Portuguese vocabulary contained more unknown words at a fixed vocabulary size. As expected the more flexible tokenizer resulted in a smaller percentage of unknown words, allowing us to use a smaller vocabulary size to speed up training (Figure 1). Of course, this results in the output lacking capitalization and punctuation, but since there was limited time for training, this seemed like a reasonable tradeoff.
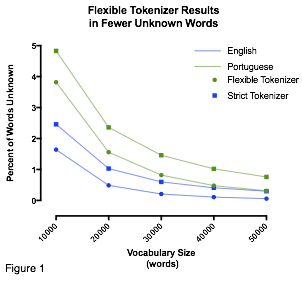
Source: Alex Nachlas
Mapping
Now that the input is tokenized into sequences of words, the next step is to convert those sequences into vectors to train the model. The vocabulary consists of the 20,000 most common English and 40,000 most common Portuguese words along with four special symbols: the unknown word symbol `_UNK,’ the padding symbol `_PAD,’ the go symbol `_GO` and the end of sentence symbol `_EOS.’ The unknown word symbol substitutes for words that are not in the vocabulary. The vocabulary sizes were chosen to be <1% of all tokens. The pad symbol is used to make inputs and outputs fit inside of our fixed length buckets. The go symbol is inserted at the start of the Portuguese decoder inputs and the end of the sentence symbol at the end of the decoder inputs.
Bucketing
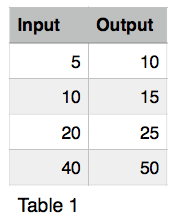
The training sentences vary in length from a single word all the way up to very long run-on sentences. TensorFlow does not currently support variable length sequences in RNNs, so this is a problem. In order to deal with these variable length inputs and outputs, the data could be padded to be the same length as the longest input and output, but this would create a lot of pad symbols in our training data and would probably mess with the output. We could also create a model for each possible length of input and output, but that would create a very large number of modules and require a much larger amount of training data. The TensorFlow framework recommends solving this problem through bucketing. Bucketing is where a model is created for each of the small number of fixed size buckets, and the input and output pairs are put into the smallest bucket they fit into and padded with the pad symbol so they are the correct size. The model uses the four bucket sizes (Table 1).
Embedding
Embedding the input vector into a smaller dimensional space can be thought of as the first layer of the network. Embedding is a very useful tool across a wide variety of natural language processing (NLP) tasks. The trained embedding of the English words contains semantic information, greatly improving the ability of the model to understand them. TensorBoard produces a nice visualization of the trained embedding using principle component analysis (Figure 2).
 Source: Alex Nachlas
Source: Alex Nachlas
Development and Training Hardware
The development of the model was completed locally using a notebook in PyCharm for Python and TensorFlow development and RStudio for exploratory data analysis. For the first attempt to train the network, I used my local machine. However, the training process using my CPU was slow. After running for several days, only a small amount of progress was made. In order to address this issue, I sucked it up and in the name of science and learning, provisioned one of the shiny new P2 instances from Amazon Web Services (AWS). I also benefited from using a nice pre-configured AMI. For the record, I went with the Bitfusion Ubuntu 14 TensorFlow image. Running on the P2.xlarge with its 61 gigs of memory and 2,496 parallel processing cores, I saw a huge improvement in training time.
Results
We trained our RNN model for more than 200,000 global steps. Our final learning rate decayed to 0.0712 and our model had a perplexity of 2.98. On the development set, the smallest bucket (5,10) had perplexity 1.65, the second bucket (10,15) had perplexity 2.80, the third bucket (20,25) had perplexity 4.83, and the largest bucket (40,50) had perplexity 5.92. Despite these results, our model performed poorly on our randomly selected test sentences, returning a large number of unknown word tokens. A native Portuguese speaker rated the translations of our neural network model on a scale of 1-5 with 5 being the best. The RNN model scored a total of 25 for an average score of 3.2.
Future Work
Our model does very poorly with translating rare words and produces too many unknown tokens. To address this, we could try to implement stemming. Another way to address this is to use more training data and to increase the vocabulary size. I think it would be interesting to try a character level output model using the 256 UTF-8 codepoints. Right now, we have a large output space and we use sampled softmax to deal with that, but even with accents, capital letters, numbers and punctuation, you still have several orders of magnitude of less possible outputs which would make training easier. Of course, now the problem you are trying to solve is harder so it’s a tradeoff, but I believe it is worth exploring.
We are simultaneously learning embeddings with our model, but they don’t have to be used for our particular task of translation. I would argue that embeddings should be trained separately because there are orders of magnitude more data to train embeddings for a single language then there are data contained in parallel corpora. Something else that would be really interesting to try is adding additional language pairs to the model using language tokens at the beginning of output.
A final potential direction for future study is instead of going deeper with our network, i.e. adding more than 3 layers (Google’s production system uses 8 with a bunch of connections to deal with vanishing gradients), we could go wide. What I mean by that is to train more models that deal directly with the input to produce outputs that could be useful to the decoder. For example, something like a part of speech tagger or a named entity recognition model. The idea behind having a very deep network is these things are a part of the network, but the benefit of training separate models is similar to the benefit of training a separate encoder; we can get more data to train them on.
Conclusion
Neural Machine Translation represents a generational leap forward in translation quality from the previous state-of-the-art SMT models. In my research, I’ve explored creating a recurrent neural network translation model from English to Portuguese. I created vocabularies, mapped a parallel corpus onto these vocabularies and separated these mapped files into different length buckets. Lastly, I trained a model that embedded inputs into a smaller dimension, encoded using 3 layers of GRU’s, decoded with attention and used sampled softmax to generate output. This project was a really fun way to learn more about the technologies that increasingly power everyday products in our lives, and if you want to learn more I recommend going through some of TensorFlow tutorials.
